

In machine learning, the dataset is not "input." It is the first version of the system's truth model.
That is why I like the way this repo documents its data. The files are not hidden behind a vague training command. The project explains where the data comes from, how the splits work, and what the labels actually mean in practice.
The Dataset Source
The project uses a Roboflow Universe dataset for Magic: The Gathering card regions. According to the repo documentation, the working version contains thousands of annotated images split into train, validation, and test subsets.
The important detail is not just the count. It is that the annotations are region-level, not card-level. The model is being taught to understand a structured object.
The Split Strategy
The repo explains the classic three-way split clearly:
train: where the model learnsvalid: where training progress is monitoredtest: where final evaluation stays honest
This matters because a detector that performs well on images it has effectively memorized is not useful. The split is one of the first safeguards against self-deception.

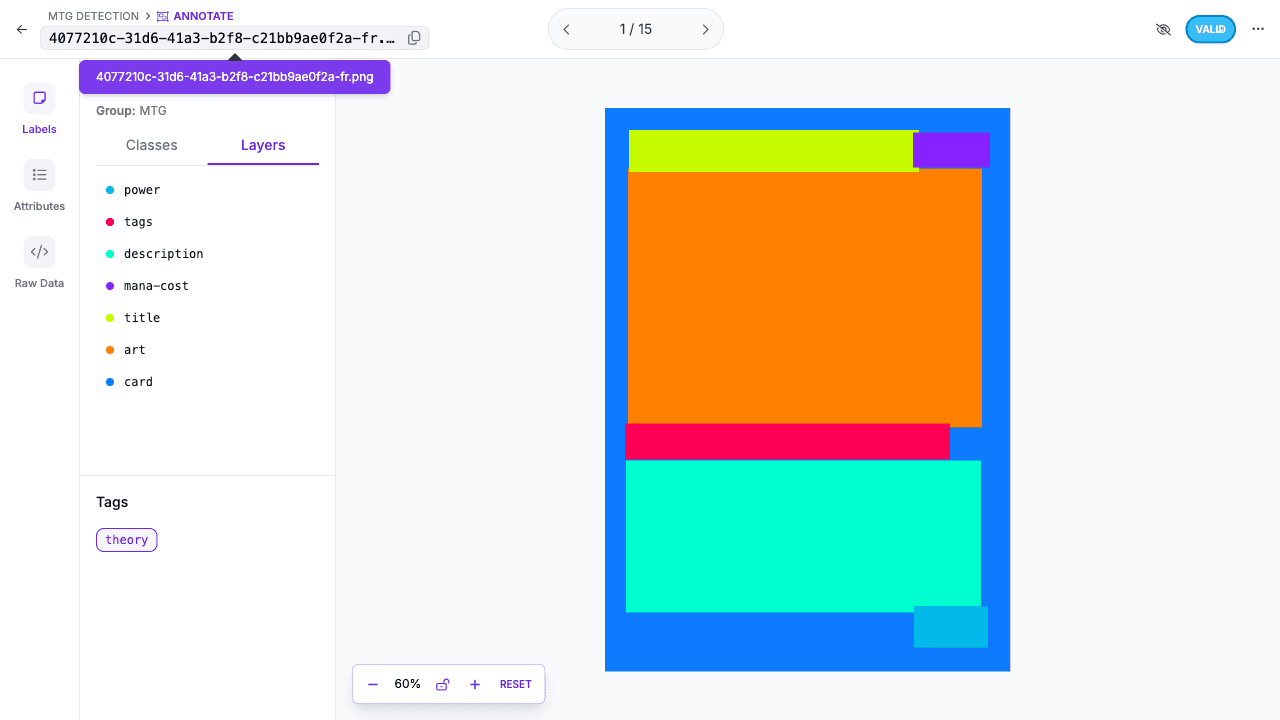
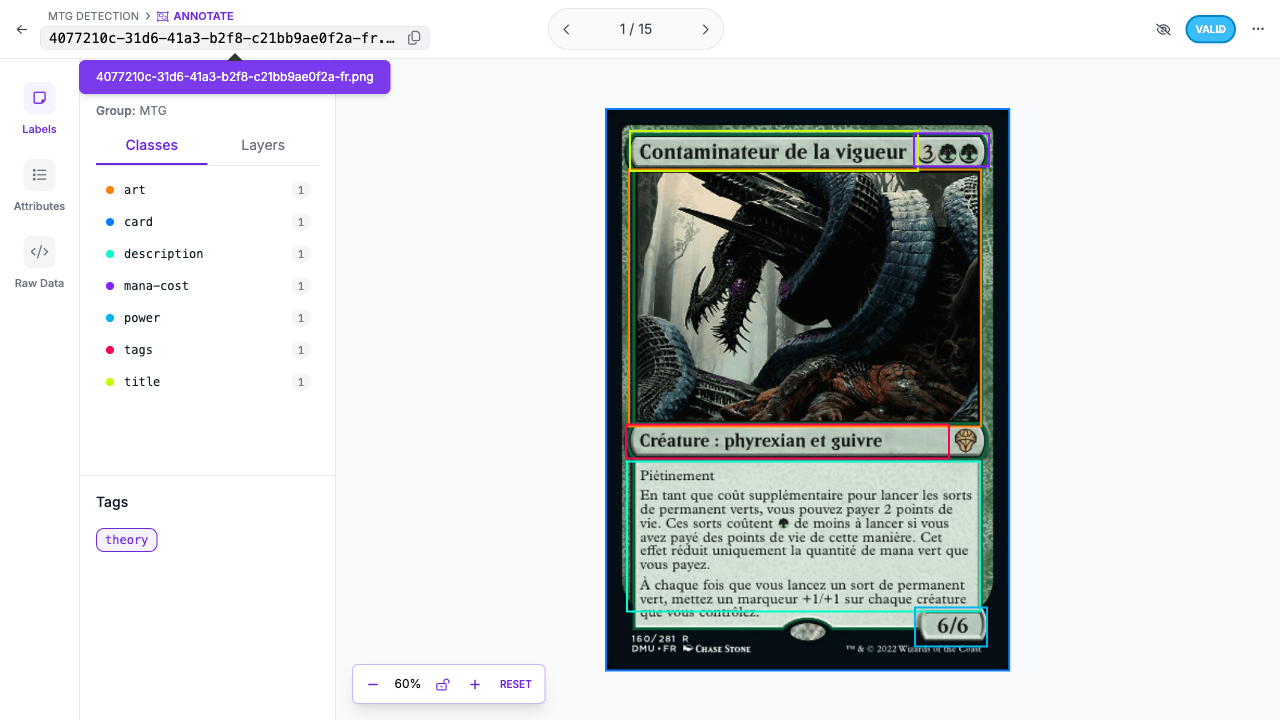
The Seven Classes
The class set is practical and downstream-aware:
| ID | Class | Why it exists |
|---|---|---|
| 0 | art | Used for visual matching |
| 1 | card | Captures the full card boundary |
| 2 | description | Preserves rules text region |
| 3 | mana-cost | Small, semantically useful detail |
| 4 | power | Another small but important region |
| 5 | tags | Type line / category signal |
| 6 | title | Primary OCR target |
This class design is stronger than a generic "card" detector because it aligns with downstream product needs. The title region exists because OCR needs a clean crop. The art region exists because print disambiguation needs one. The classes reflect system requirements, not academic neatness.

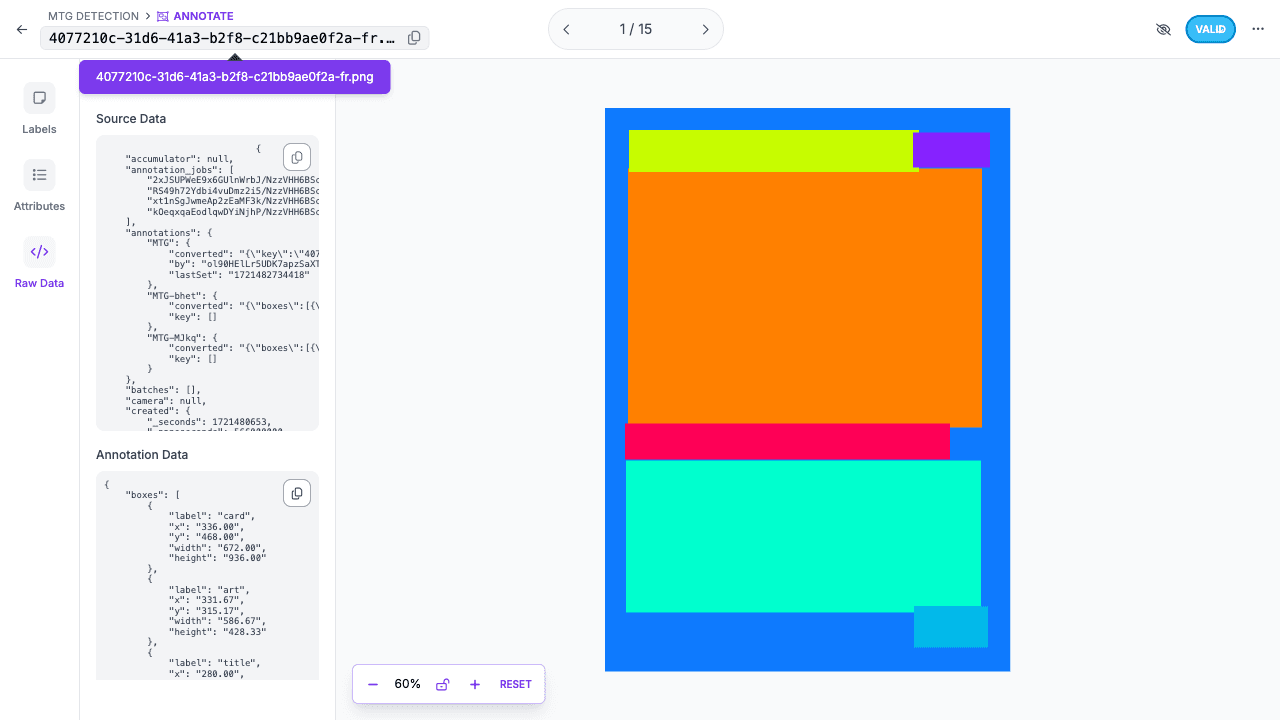
What a YOLO Label Actually Stores
The file format is minimal:
All coordinates are normalized to [0, 1], which keeps the labels resolution-independent.
That simplicity is one of YOLO's practical strengths. The same simplicity is also unforgiving. If the label is sloppy, the model will faithfully learn sloppy targets.

Annotation Quality Is the Hidden Bottleneck
One of the most revealing details in the repo is the performance gap between relaxed and strict metrics:
- strong
mAP50 - meaningfully lower
mAP50-95
That pattern is common when the detector is finding roughly the right region but cannot consistently achieve near-pixel-perfect overlap. For large boxes, that is often acceptable. For small boxes like mana-cost and power, a few bad pixels matter a lot.
This is why the repo repeatedly returns to annotation quality in the metrics and training documents. Bigger models do not magically fix inconsistent boxes.
Data Quality Checks Matter More Than People Admit
The exploration scripts in this repo are not filler. They generate sample grids, class distributions, and quality checks. That is the right instinct.
Before tuning augmentations or scaling to cloud GPUs, an engineer should be able to answer:
- Are labels missing?
- Are some classes underrepresented?
- Are small boxes consistently too loose or too tight?
- Do train and validation samples look like the same world?
That is basic engineering hygiene. Without it, parameter tuning becomes expensive superstition.

Annotation Noise and Small Objects
The hardest classes in this project are not surprising. Small semantic regions are always more fragile:
mana-costpowertitletags
These classes compress a lot of meaning into a small area. Any mismatch in labeling, cropping, camera angle, or resolution hurts disproportionately.

This is also why the training strategy later leans on augmentations like mosaic, multi-scale training, and geometric transforms. Those choices are trying to help the model survive real-world variance without pretending the labels are perfect.
The Correction Workflow Is Part of the Architecture
One of my favorite details in the project is the explicit correction loop:
- download test images
- export predictions
- review in Label Studio
- merge corrected labels
- retrain
That is the right way to think about quality improvement. The model is not just trained once. The dataset and the detector can improve together.
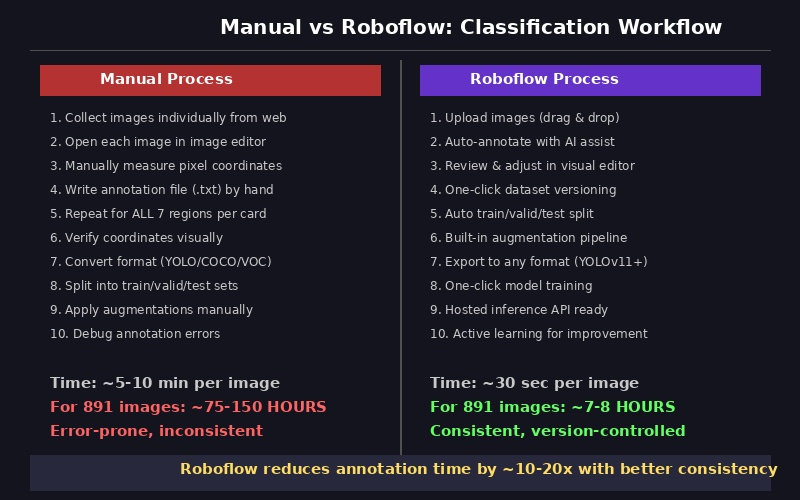
That is the baseline cost. It makes the value of assisted tooling obvious, but it also explains why teams get tempted to trust automation too early.
The right takeaway is not "automation replaces judgment." It is "automation compresses the first pass, so human review can focus on the hard cases."
Conclusion
A detector learns whatever definition of reality the dataset encodes. If the labels are thoughtful, consistent, and close to the downstream task, the model has a chance. If the labels are noisy, even a strong architecture will plateau early.
This repo gets the important part right: it treats the dataset as a first-class engineering artifact.
In the next article, we move from the data itself to the choices that shape training: transfer learning, augmentation, optimization, and the experiments that pushed this detector to its best result.
Further Reading
- Dataset and file formats:
docs/architecture.md - Concepts and data splits:
docs/concepts.md - Metrics discussion:
docs/metrics-guide.md - Roboflow documentation: https://docs.roboflow.com/
- SSD paper: https://arxiv.org/abs/1512.02325
- Feature Pyramid Networks: https://arxiv.org/abs/1612.03144