

Series Navigation: MPSC Queue | MPMC Queue
MPMC Queues: The Final Boss
When Everyone Fights Everyone: Dual CAS Coordination
We've conquered SPSC (one-to-one) and MPSC (many-to-one). Now comes the final boss: MPMC—Multi-Producer Multi-Consumer. Everyone writes. Everyone reads. Everyone competes on both sides of the queue.
If SPSC maps neatly to dedicated pipeline stages and MPSC maps to "many sources feeding a single aggregator," then MPMC is what you find in task execution frameworks, thread pools, web server request queues, and any system where multiple threads both produce work and consume it. This is where most naive implementations crumble. In this chapter we'll look at why, and then build a version that doesn't.
Understanding MPMC Queue Challenges
This section explores the fundamental problems with MPMC queue design.
The double contention nightmare
MPMC is uniquely challenging because you have contention on both ends of the queue:
The naive solution is to protect both ends with a single global lock:
The result is complete serialization:
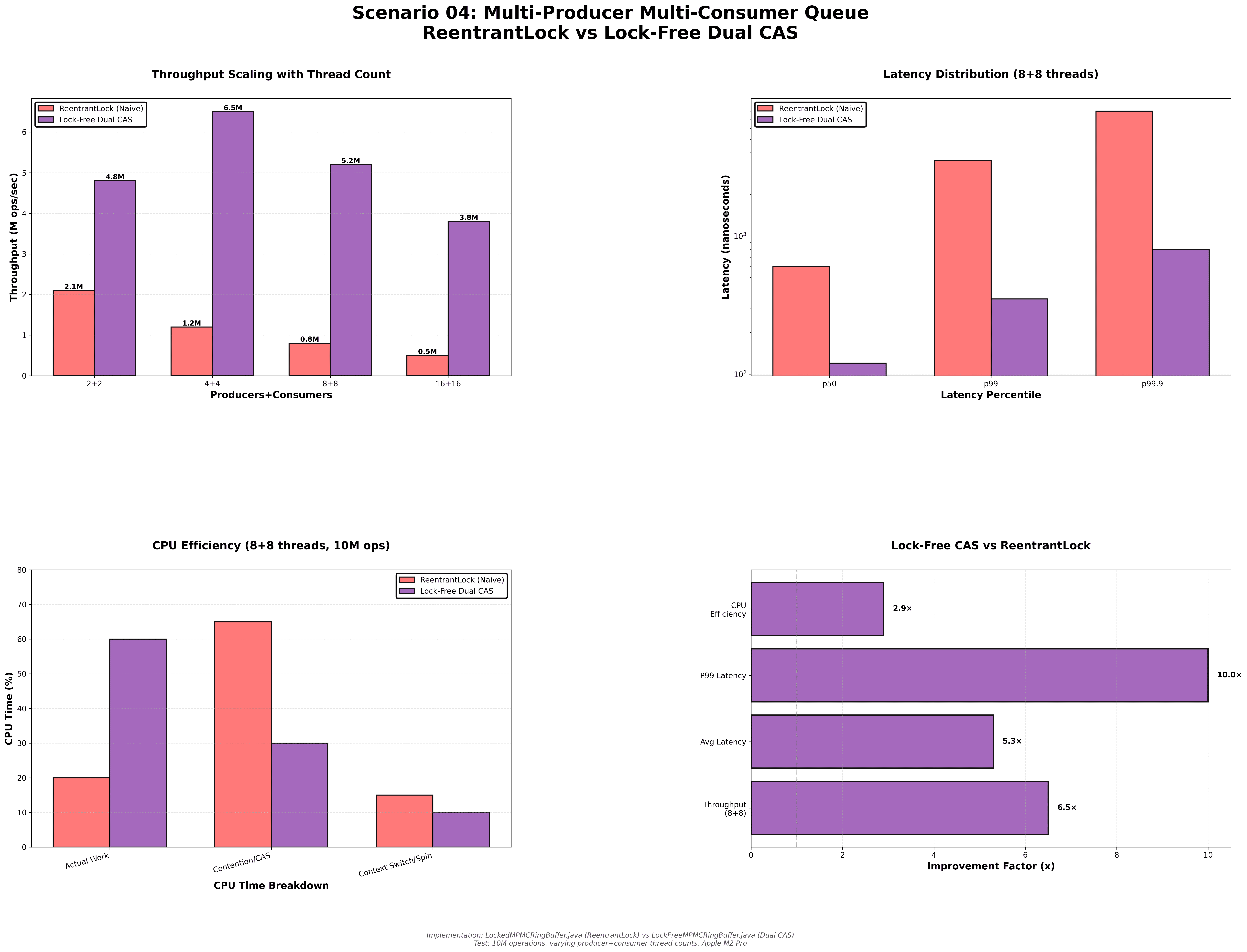
With 8 producers + 8 consumers, throughput collapses to 800K ops/sec. Adding threads makes it slower because you've turned a concurrent problem into a strictly serialized one guarded by a hot lock that all participants share.
Lock-Free MPMC Implementation
This section covers the techniques needed to build high-performance MPMC queues.
The lock-free solution: dual CAS
The core insight for MPMC is that producers only need to contend with other producers, and consumers only need to contend with other consumers. There is no reason for a consumer to grab the same mutex as a producer, as long as we can safely coordinate head and tail indices. That leads us to a dual CAS design: one CAS for claimed write slots, and a separate CAS for claimed read slots.
Now producers and consumers operate independently:
No global lock. No serialization between the "send" side and the "receive" side. Just CAS-based coordination among peers on each end.
Performance and Optimization
Comprehensive analysis of how lock-free MPMC queues outperform traditional approaches.
The performance revolution
Using the same benchmark harness as for MPSC, we test 4 producers + 4 consumers and 8 producers + 8 consumers, each performing 10 million operations.
Throughput
Benchmark Environment: These results were obtained on modern x86-64 hardware. Performance may vary based on CPU architecture, JVM version, GC configuration, and workload characteristics. Always benchmark with your specific use case.
The lock-free design is 6.5× faster, but more importantly, lock-free scales while the locked version collapses as you add threads. Instead of turning additional cores into lock-waiters, the dual CAS scheme lets both producer and consumer sides exploit more parallelism.
Latency
That p99.9 is where MPMC systems traditionally die. In the locked version, you see 12 microseconds due to cascading lock waits: producers and consumers both pile up behind the same mutex, amplifying each other’s delays. In the lock-free version, those long outliers shrink to 1.2 microseconds, driven primarily by brief CAS retry bursts rather than serialized lock handoffs.
CPU efficiency
Result: 3.25× better CPU utilization (35% wasted vs 80% wasted)
Lock-free still has coordination cost—nothing is free—but it wastes 35% of CPU time instead of 80%. On a 16-thread system, that's the difference between burning ~13 cores on overhead versus ~5.6 cores, which often decides whether you can scale on a single machine or need to shard across multiple.
Coordination Mechanisms
Understanding the fine details of making MPMC queues correct and safe.
The sequence number coordination
The dual CAS scheme above ensures that producers and consumers don’t step on each other’s indices, but we still need to guard against out-of-order writes and reads on individual slots.
Consider this:
The fix is the same per-slot sequence number idea we used in MPSC, applied symmetrically:
This ensures that producers never overwrite active slots, as the sequence number check prevents a producer from writing to a slot until the consumer has finished reading from it in the previous lap. Consumers never read incomplete data, as the sequence number check ensures that a consumer only reads from a slot after the producer has finished writing to it. The ring can be reused lap after lap without confusion, since the sequence encodes which "round" each slot belongs to, allowing the buffer to cycle through multiple complete passes without losing track of slot ownership.
Practical Guidance and Applications
Knowing when and how to apply MPMC queue patterns effectively.
When to use MPMC
MPMC queues are perfect for task execution frameworks following ThreadPoolExecutor-style patterns, where multiple threads submit tasks and multiple worker threads consume them. Web server request queues represent another ideal use case, where multiple acceptors handle incoming connections and multiple handlers process requests concurrently. Work-stealing schedulers benefit from MPMC queues, allowing multiple submitters to enqueue work while multiple workers dequeue and execute tasks. Event processing systems with multiple sources feeding multiple processors also represent a natural fit for MPMC coordination.
MPMC is not suitable when you have a single producer and single consumer, as SPSC is simpler and faster for that scenario. When you have multiple producers but only a single consumer, MPSC avoids consumer-side contention and is the better choice. For low thread counts with fewer than four total threads, locks are fine and simpler to implement and maintain. If dynamic sizing is needed, ring buffers are fixed capacity and you pay for that simplicity, so MPMC may not be appropriate.
The rule of thumb: If you have 4+ producers AND 4+ consumers with high throughput needs, and you're willing to pay the complexity cost, use a lock-free MPMC.
Real-World Application Examples
See how MPMC queues deliver value in production systems.
Real-world impact: task execution
Here’s what happened when we rebuilt a task execution framework to use a lock-free MPMC queue instead of a global lock:
Before (Locked):
After (Lock-Free MPMC):
Result: 6.5× more throughput, 7.8× better latency, and 99% fewer timeouts. Same hardware, same workload mix, just a fundamentally better coordination mechanism at the queue.
Summary and Future Directions
Reflections on the MPMC queue design and what comes next in the series.
Closing thoughts
MPMC is the hardest coordination pattern in this series because everyone competes on both sides of the queue. One global lock is simple to reason about and easy to implement, but it serializes all operations and quickly becomes catastrophically slow under load.
Dual CAS lets producers and consumers operate independently, with contention only among their own kind. The cost is complexity: CAS loops, per-slot sequence numbers, and careful attention to memory ordering are non-trivial to get right and non-trivial for teams to maintain. The reward, however, is substantial: 6.5× throughput and 10× better tail latency with 16 threads in our benchmarks, plus significantly better CPU utilization.
In our series so far, we've covered off-heap ring buffers that eliminated GC pauses by moving data structures outside the heap, wait-free SPSC queues that are optimal for one-to-one coordination and deliver 6.4× throughput improvements, lock-free MPSC queues that use CAS for many-to-one coordination and deliver 4.9× throughput improvements, and lock-free MPMC queues that use dual CAS for many-to-many coordination and deliver 6.5× throughput improvements.
Next: Event Pipelines—chaining multiple SPSC queues (or ring segments) for staged processing. Think LMAX Disruptor: one of the most influential patterns in high-throughput event-driven systems.
May your CAS operations succeed and your queues never block.
Continue Your Off-Heap Journey
Ready to explore more advanced concurrency patterns? Check out the related queue implementations in this series:
Series Navigation: MPSC Queue | MPMC Queue
Further Reading
Looking for the deep-dive? This is the introductory version. The production-grade MPMC implementation covers dual-CAS coordination, work-stealing integration, and production benchmarks.
- Michael, M.M. & Scott, M.L. (1996). "Simple, Fast, and Practical Non-Blocking and Blocking Concurrent Queue Algorithms" — ACM PODC
- Kogan, A. & Petrank, E. (2011). "Wait-Free Queues with Multiple Enqueuers and Dequeuers" — PPoPP
- JCTools MPMC Queue – Production-grade implementation
- Java
ThreadPoolExecutor– Uses related coordination patterns under the hood - Disruptor MPMC Mode – Alternative approach from the Disruptor library
Repository: techishthoughts-org/off_heap_algorithms